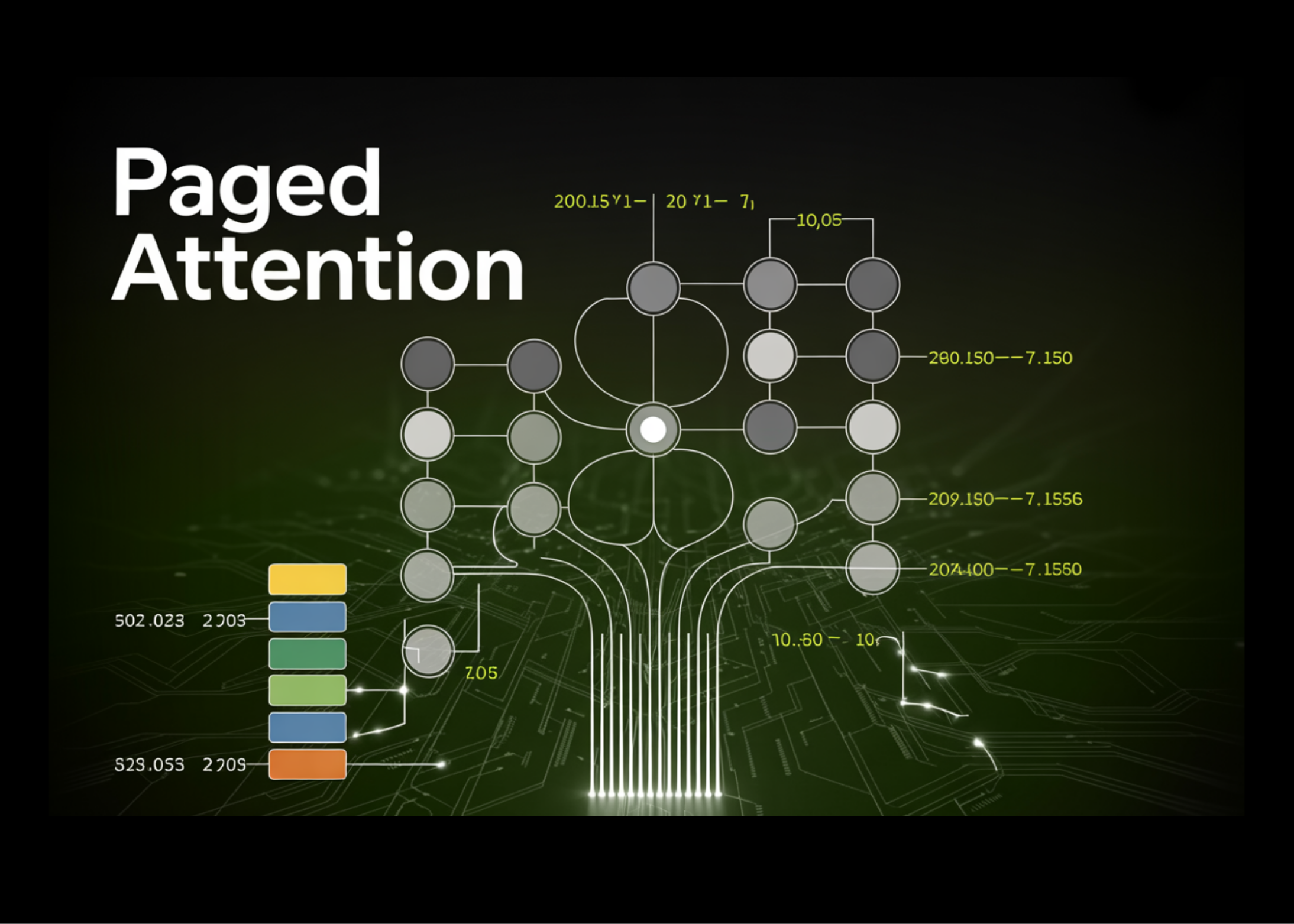
Paged Attention in Large Language Models LLMs
When running LLMs at scale, the real limitation is GPU memory rather than compute, mainly because each request requires a KV cache to store token-level data. In traditional setups, a large fixed me...
Source: MarkTechPost
When running LLMs at scale, the real limitation is GPU memory rather than compute, mainly because each request requires a KV cache to store token-level data. In traditional setups, a large fixed memory block is reserved per request based on the maximum sequence length, which leads to significant unused space and limits concurrency. Paged Attention […] The post Paged Attention in Large Language Models LLMs appeared first on MarkTechPost.













![An inside look at a ConsenSys-funded web 3.0 accelerator [INTERVIEW]](https://cryptoslate.com/wp-content/uploads/2019/09/ethereum-space-social.jpg)